为什么很多团队觉得代理IP接入API很难?
多数接入困难不是因为API本身复杂,而是把"厂商差异"和"协议原理"混在一起了。
代理IP服务的底层协议就那么几种:HTTP/HTTPS正向代理、SOCKS5代理。不同厂商的差异集中在两个层面:鉴权方式和IP获取方式。把这两层拆开看,接入逻辑就清晰了。
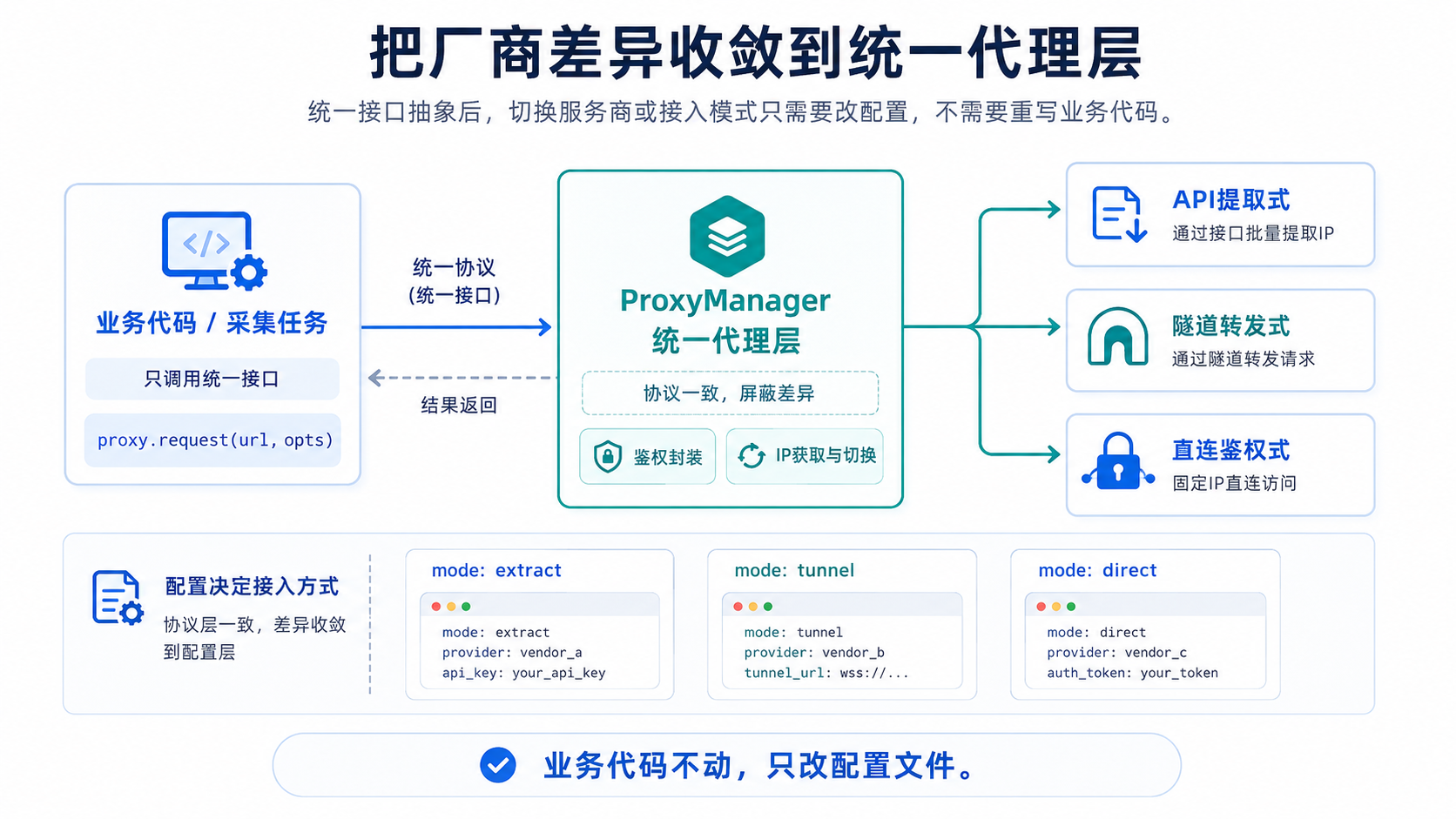
实际企业级数据采集场景中,一个舆情监测系统可能同时对接3-5家代理服务商。如果每家都写一套独立的接入代码,后期维护成本会指数级上升。更合理的做法是抽象出统一的代理层接口,把厂商差异收敛到配置文件里。
| 常见误区 | 实际情况 |
|---|---|
| 每家API都要从头学 | 底层协议一致,差异只在参数和鉴权 |
| 接入代码越多越复杂 | 抽象出代理层后,新增厂商只改配置 |
| 文档看不懂就是API难 | 90%的问题出在鉴权环节,不是请求本身 |
代理IP的API接入一共有几种模式?
主流的代理IP API接入模式可以归纳为三种:API提取式、隧道转发式、直连鉴权式。
第一种:API提取式。 通过HTTP接口请求一批可用的代理IP地址和端口,拿到列表后自行管理和轮换。这是最传统也最灵活的模式,适合需要精细控制IP使用策略的场景。
第二种:隧道转发式。 连接一个固定的代理网关地址,每次请求自动分配不同的出口IP。不需要自己维护IP池,服务端自动完成IP切换和存活管理。适合高并发、不想管IP池状态的场景。
第三种:直连鉴权式。 拿到固定的代理IP和端口,通过账密或白名单方式鉴权后直接使用。IP不变,适合需要会话保持或长连接的场景。
| 接入模式 | 获取IP方式 | IP管理责任 | 典型适配场景 |
|---|---|---|---|
| API提取式 | HTTP接口批量获取 | 客户端自管 | 网站采集器、定时批量任务 |
| 隧道转发式 | 固定网关自动分配 | 服务端自管 | 舆情监测、高并发实时采集 |
| 直连鉴权式 | 固定IP+端口 | 无需管理 | 广告监测、会话保持型任务 |

API提取式怎么调?
API提取式的核心流程只有三步:请求IP列表、解析返回结果、将IP填入采集请求的代理参数。
第一步:构造提取请求。
一般是一个GET请求,参数包括:提取数量、地区筛选、协议类型、返回格式。
GET https://api.example.com/getip?num=10&protocol=https&format=json®ion=beijing常见的返回格式有JSON、TXT纯文本、XML三种。JSON最便于程序解析,推荐优先选择。
第二步:解析返回结果。
典型的JSON返回结构:
{
"code": 0,
"data": [
{"ip": "120.xx.xx.01", "port": 8080, "expire": "2026-06-23 15:30:00"},
{"ip": "183.xx.xx.55", "port": 9090, "expire": "2026-06-23 15:30:00"}
]
}需要关注的字段:ip和port是代理地址,expire是过期时间。过期时间决定了本地IP池的淘汰策略。
第三步:在采集请求中使用代理。
Python示例:
import requests
proxy_ip = "120.xx.xx.01"
proxy_port = 8080
proxies = {
"http": f"http://{proxy_ip}:{proxy_port}",
"https": f"http://{proxy_ip}:{proxy_port}"
}
response = requests.get("https://target-site.com/data", proxies=proxies, timeout=10)本地IP池管理要点:
- 提取后立即写入本地缓存,标记过期时间
- 每次使用前校验是否过期,过期的直接淘汰
- 设置最低水位线,低于阈值时自动触发下一次提取
- 企业级场景建议用Redis做IP池存储,支持TTL自动过期
在网站采集器场景中,API提取式的优势是可以按目标站点的访问频率控制策略来精确分配IP。比如某招投标数据平台对单IP每分钟请求数有严格限制,用提取式可以按1:1分配IP和任务,避免单IP过载。

隧道转发式怎么调?
隧道代理的使用方式更简单:只需要连接一个固定的代理网关地址,不用自己维护IP池。
连接方式:
隧道代理通常提供一个固定域名+端口作为入口,鉴权方式一般是用户名密码或者IP白名单。
import requests
# 账密鉴权方式
proxies = {
"http": "http://username:password@tunnel.example.com:10000",
"https": "http://username:password@tunnel.example.com:10000"
}
response = requests.get("https://target-site.com/data", proxies=proxies, timeout=10)每次请求经过隧道网关时,服务端自动从IP池中分配一个出口IP。对客户端来说,代理地址始终不变,IP切换完全透明。
隧道代理的请求头传参:
部分服务商支持通过请求头传递控制参数,比如指定出口地区、指定会话保持时长。
headers = {
"Proxy-Region": "shanghai",
"Proxy-Session": "abc123", # 同一session值在有效期内保持同一出口IP
"Proxy-Session-Duration": "300" # 会话保持300秒
}
response = requests.get(
"https://target-site.com/data",
proxies=proxies,
headers=headers,
timeout=10
)隧道转发模式在舆情监测场景中表现突出。比如需要同时监控50个新闻源站点的更新,每分钟发起上千次请求,如果用API提取式需要维护一个庞大的本地IP池并处理过期淘汰。隧道模式把这些工作全部交给服务端,客户端只需要关注业务逻辑。
隧道模式的局限:
- 无法自主选择具体IP,精细化控制能力弱于API提取式
- 依赖服务端的IP调度质量,出现问题排查链路更长
- 部分场景需要固定IP时不适用
直连鉴权式怎么调?
直连鉴权式适用于需要固定IP的场景,IP地址在购买时就已经确定。
两种鉴权方式:
| 鉴权方式 | 配置方法 | 安全性 | 适配场景 |
|---|---|---|---|
| IP白名单 | 在服务商后台添加客户端出口IP | 高,无密码传输 | 服务器IP固定的企业环境 |
| 账密认证 | 在代理URL中带用户名密码 | 中,密码明文传输需加密通道 | IP不固定的开发测试环境 |
IP白名单方式:
先在服务商后台将客户端的出口IP加入白名单,然后直接使用代理地址,无需带账密。
# 白名单鉴权,客户端IP已在后台授权
proxies = {
"http": "http://fixed-proxy.example.com:8888",
"https": "http://fixed-proxy.example.com:8888"
}
response = requests.get("https://target-site.com/data", proxies=proxies, timeout=10)账密认证方式:
# 账密鉴权
proxies = {
"http": "http://user01:pass123@fixed-proxy.example.com:8888",
"https": "http://user01:pass123@fixed-proxy.example.com:8888"
}广告监测场景中,直连鉴权式的优势很明显。比如需要持续监控某电商平台在特定城市的广告投放素材,用固定IP可以保持稳定的访问环境,避免因IP变化导致目标站点返回不同的广告内容,影响监测数据的一致性。
三种模式在实际项目中怎么选?
没有哪种模式绝对更好,选择取决于业务场景的核心约束。
按并发量选:
- 日均请求量 < 1万次:直连鉴权式或API提取式均可
- 日均请求量1万-100万次:API提取式配合本地IP池管理
- 日均请求量 > 100万次:隧道转发式,省去IP池维护开销
按IP稳定性需求选:
- 需要固定IP(会话保持、环境一致性):直连鉴权式
- 需要大量不同IP(应对访问频率限制):API提取式或隧道转发式
- 不关心具体IP、只要能通:隧道转发式
按运维成本选:
| 维度 | API提取式 | 隧道转发式 | 直连鉴权式 |
|---|---|---|---|
| 客户端代码复杂度 | 中,需写IP池管理 | 低,固定代理地址 | 低,固定代理地址 |
| 服务端依赖程度 | 低 | 高 | 中 |
| 故障排查难度 | 低,IP可追溯 | 中,出口IP不可控 | 低,IP固定 |
| 适合团队规模 | 有专职运维的中大团队 | 人少活多的精简团队 | 小规模固定任务 |
实际工程中,混合使用是常态。比如一个广告监测系统,核心监控链路用直连鉴权式保证IP稳定,补充数据采集用隧道转发式提高效率,历史数据回补用API提取式控制成本。
接入调试阶段最容易踩哪些坑?
代理IP接入调试阶段,80%的问题集中在四个环节。
坑1:鉴权失败返回407/403。
最常见的原因是IP白名单没有更新。如果客户端的出口IP是动态的,白名单鉴权就会间歇性失败。解决方案:动态IP环境优先用账密认证,或者部署一个固定出口IP的代理中转层。
坑2:HTTPS请求通过HTTP代理失败。
HTTP代理处理HTTPS请求时走的是CONNECT隧道,不是普通的GET转发。如果代理服务端不支持CONNECT方法,HTTPS请求就会失败。排查方式:先用HTTP目标测通,再切HTTPS目标,缩小问题范围。
坑3:超时但代理本身是通的。
代理连接成功不等于目标站点可达。排查顺序:
- 用curl直接测代理连通性:
curl -x http://proxy_ip:port http://httpbin.org/ip - 确认目标站点本身是否可访问
- 检查DNS解析是否通过代理走还是本地走
- 调整超时参数,连接超时和读取超时分开设置
response = requests.get(
"https://target-site.com/data",
proxies=proxies,
timeout=(5, 30) # 连接超时5秒,读取超时30秒
)坑4:并发场景下代理连接池耗尽。
高并发采集时,如果每个请求都新建TCP连接,代理服务端的连接数很快被打满。解决方案:使用requests.Session()复用连接,或者在异步框架中配置连接池上限。
session = requests.Session()
session.proxies = proxies
# 复用session发起多次请求
for url in url_list:
response = session.get(url, timeout=10)怎么用代码实现一个通用的代理调用层?
把三种模式的差异封装成配置,业务代码只调统一接口。
import requests
import time
import json
class ProxyManager:
def __init__(self, config):
self.mode = config["mode"] # extract / tunnel / direct
self.config = config
self.ip_pool = []
def get_proxy(self):
if self.mode == "tunnel":
auth = f"{self.config['user']}:{self.config['pass']}"
return {"http": f"http://{auth}@{self.config['gateway']}",
"https": f"http://{auth}@{self.config['gateway']}"}
elif self.mode == "direct":
addr = self.config["proxy_addr"]
if self.config.get("auth_type") == "password":
auth = f"{self.config['user']}:{self.config['pass']}"
return {"http": f"http://{auth}@{addr}",
"https": f"http://{auth}@{addr}"}
return {"http": f"http://{addr}", "https": f"http://{addr}"}
elif self.mode == "extract":
if not self.ip_pool or self._pool_low():
self._fetch_ips()
ip_info = self.ip_pool.pop(0)
addr = f"{ip_info['ip']}:{ip_info['port']}"
return {"http": f"http://{addr}", "https": f"http://{addr}"}
def _fetch_ips(self):
resp = requests.get(self.config["extract_url"], timeout=10)
data = resp.json()
self.ip_pool.extend(data.get("data", []))
def _pool_low(self):
return len(self.ip_pool) < self.config.get("min_pool", 5)配置文件示例:
{
"mode": "tunnel",
"gateway": "tunnel.example.com:10000",
"user": "your_username",
"pass": "your_password"
}这样做的好处是,切换代理服务商或切换接入模式时,业务代码完全不用动,只改配置文件。在网站采集器场景中,一个采集引擎可能需要同时调用多个代理源来保证采集稳定性,统一代理层可以做到一次抽象、多源切换。
接入完成后怎么验证代理是否生效?
验证代理是否正常工作,需要确认三件事:出口IP已变更、目标站点可达、响应数据正确。
验证步骤:
- 确认出口IP变更: 请求
http://httpbin.org/ip或https://ifconfig.me,对比返回的IP和本机IP是否不同 - 确认目标站点可达: 用代理访问实际目标URL,检查HTTP状态码是否为200
- 确认响应内容正确: 检查返回的页面内容是否是目标页面,而不是代理服务商的错误页或验证码页面
# 快速验证脚本
def verify_proxy(proxies):
# 验证出口IP
try:
r = requests.get("http://httpbin.org/ip", proxies=proxies, timeout=10)
print(f"出口IP: {r.json()['origin']}")
except Exception as e:
print(f"代理连接失败: {e}")
return False
# 验证目标站点
try:
r = requests.get("https://your-target-site.com", proxies=proxies, timeout=15)
print(f"目标站点状态码: {r.status_code}")
print(f"响应长度: {len(r.text)} 字符")
return r.status_code == 200
except Exception as e:
print(f"目标站点访问失败: {e}")
return False持续监控建议:
- 每5分钟跑一次代理健康检查,记录成功率和响应时间
- 成功率低于95%时触发告警
- 响应时间P99超过3秒时考虑切换代理源或降低并发
- 日志中记录每次请求使用的代理IP,方便事后排查
代理IP的API接入并不复杂。把协议、鉴权、IP管理三个层拆开理解,再根据业务场景的并发量、稳定性需求、运维成本三个约束条件选择对应的接入模式,整个接入过程就从"读文档猜参数"变成了"填配置跑测试"。
FAQ
Q:API提取式和隧道转发式可以混合使用吗?
可以,而且在企业级采集中很常见。核心链路用隧道模式保证稳定性和开发效率,批量数据回补任务用API提取式控制成本。关键是在代码层做好代理源的抽象封装,让业务逻辑和代理模式解耦。
Q:代理IP接入时SOCKS5和HTTP代理有什么区别?
HTTP代理只处理HTTP/HTTPS流量,SOCKS5代理可以转发任意TCP流量。如果采集任务只涉及Web页面和API接口,HTTP代理就够了。如果涉及非HTTP协议的数据传输,需要选择支持SOCKS5的服务。Python中使用SOCKS5代理需要额外安装PySocks库。
Q:白名单鉴权和账密鉴权哪个更安全?
白名单鉴权不传输密码,安全性更高,但前提是客户端出口IP固定。如果是云服务器、IDC机房等IP不变的环境,优先用白名单。如果是开发机、动态IP环境,账密鉴权更实用,但建议走HTTPS通道避免密码被中间链路截取。
Q:并发请求时代理连接数有上限吗?
有。大多数代理服务商会限制单账户的并发连接数,超过上限后新请求会被拒绝或排队。企业级场景中,建议在采集框架中配置连接池上限,并设置重试机制。用requests.Session()或异步框架的连接池参数可以有效管理并发连接。
Q:代理IP返回数据乱码怎么排查?
大概率是编码问题而非代理问题。先确认目标站点的Content-Type头中声明的编码格式,再对比response.encoding和response.apparent_encoding是否一致。如果不一致,手动指定编码:response.encoding = response.apparent_encoding。只有排除编码问题后,才考虑是否是代理服务端篡改了响应内容。
Q:怎么判断代理IP是否已经被目标站点限制了?
三个信号:返回状态码变为403/429、返回内容变成验证码页面、响应时间突然异常增长。建议在采集代码中加入状态码和内容校验逻辑,发现异常后自动切换代理IP并标记失效IP。API提取模式下可以直接丢弃该IP,隧道模式下需要等待服务端自动切换。




